Our research paper "AQUA: A Large Language Model for Aquaculture & Fisheries" is now available on arXiv (arXiv:2507.20520).
Paper Overview
The paper presents AQUA — the first large language model specifically designed for the aquaculture and fisheries domain. Key contributions include:
AQUADAPT Framework
We introduce AQUADAPT (Agentic Framework for generating and refining high-quality synthetic data), a novel approach to creating domain-specific training data using agentic AI pipelines. This framework enables:
- Automated generation of high-quality QA pairs from domain literature
- Multi-stage verification and refinement of training data
- Scalable data creation across 11 aquaculture sub-domains
Training Data
- 55,000+ curated documents from web sources and open-access publications
- 3 million+ expert-verified QA pairs covering the full aquaculture taxonomy
- ~1 billion training tokens processed during fine-tuning
Benchmark Results
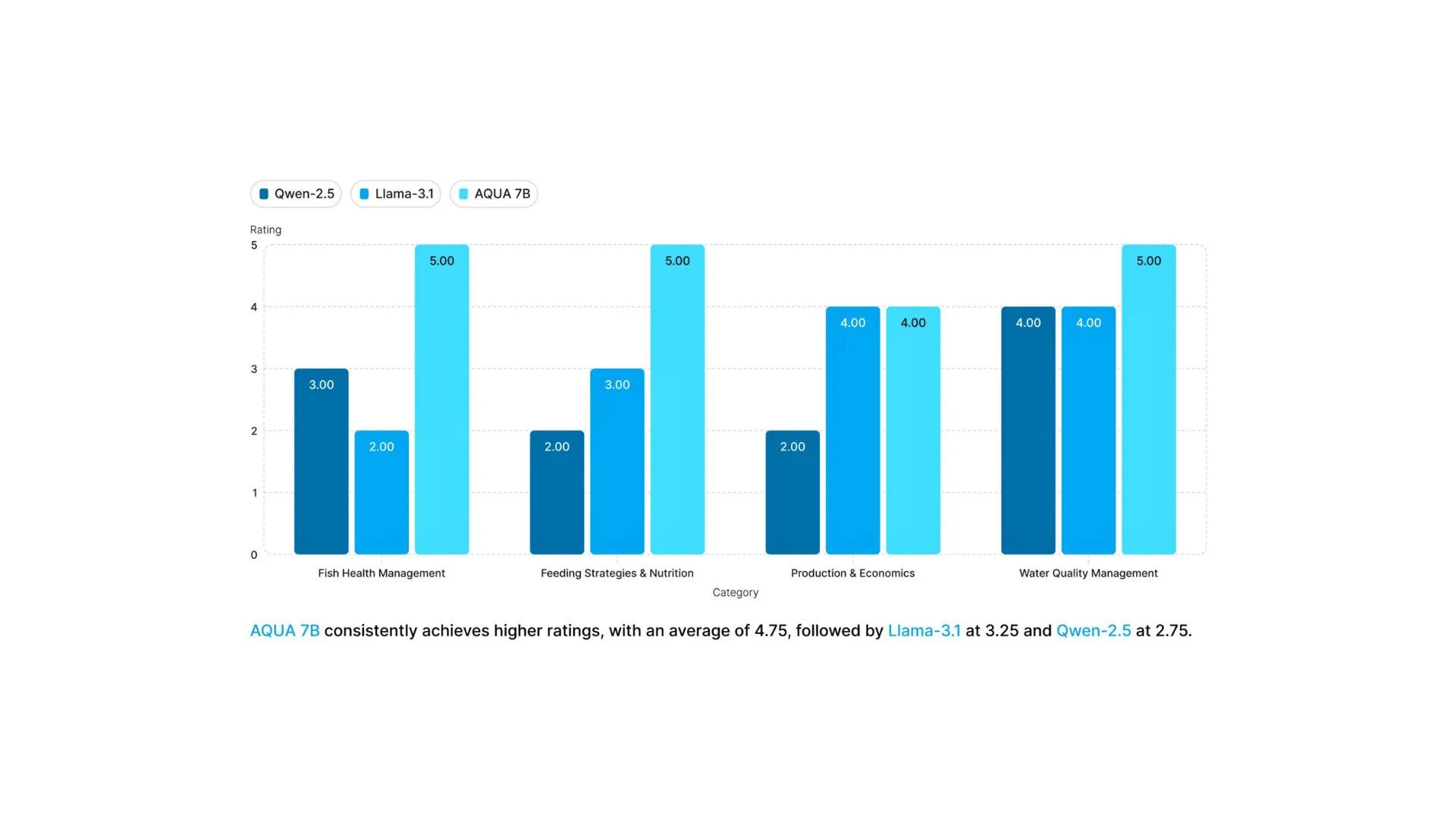
AQUA-7B demonstrates significant improvements over general-purpose models:
- 30-40% higher accuracy on domain-specific tasks compared to LLaMA 3.1 8B and Qwen 2.5 7B
- 95% average accuracy on aquaculture domain benchmarks
- BLEU-4: 49.19 — Strong multiword phrase fidelity
- ROUGE-1: 51.45 — High coverage of key domain terms
Model Architecture
- Base Model: Mistral-7B-Instruct-v0.3
- Fine-tuning: LoRA with AdamW optimizer
- Hardware: 8× NVIDIA H200 GPUs
- Training Time: ~32 hours
Read the Paper
- arXiv: arxiv.org/abs/2507.20520
- PDF: arxiv.org/pdf/2507.20520
Citation
If you use AQUA in your research, please cite our paper. The full BibTeX citation is available on our Research page.